map原理分析
map 结构体
type hmap struct { |
bmap不只tophash还有两个方法 overflow 和setoverflow
func (b *bmap) overflow(t *maptype) *bmap { |
hmap中的buckets中的原色bucket就是bmap,即 buckets[0],bucket[1],… bucket[2^B-1]如下图
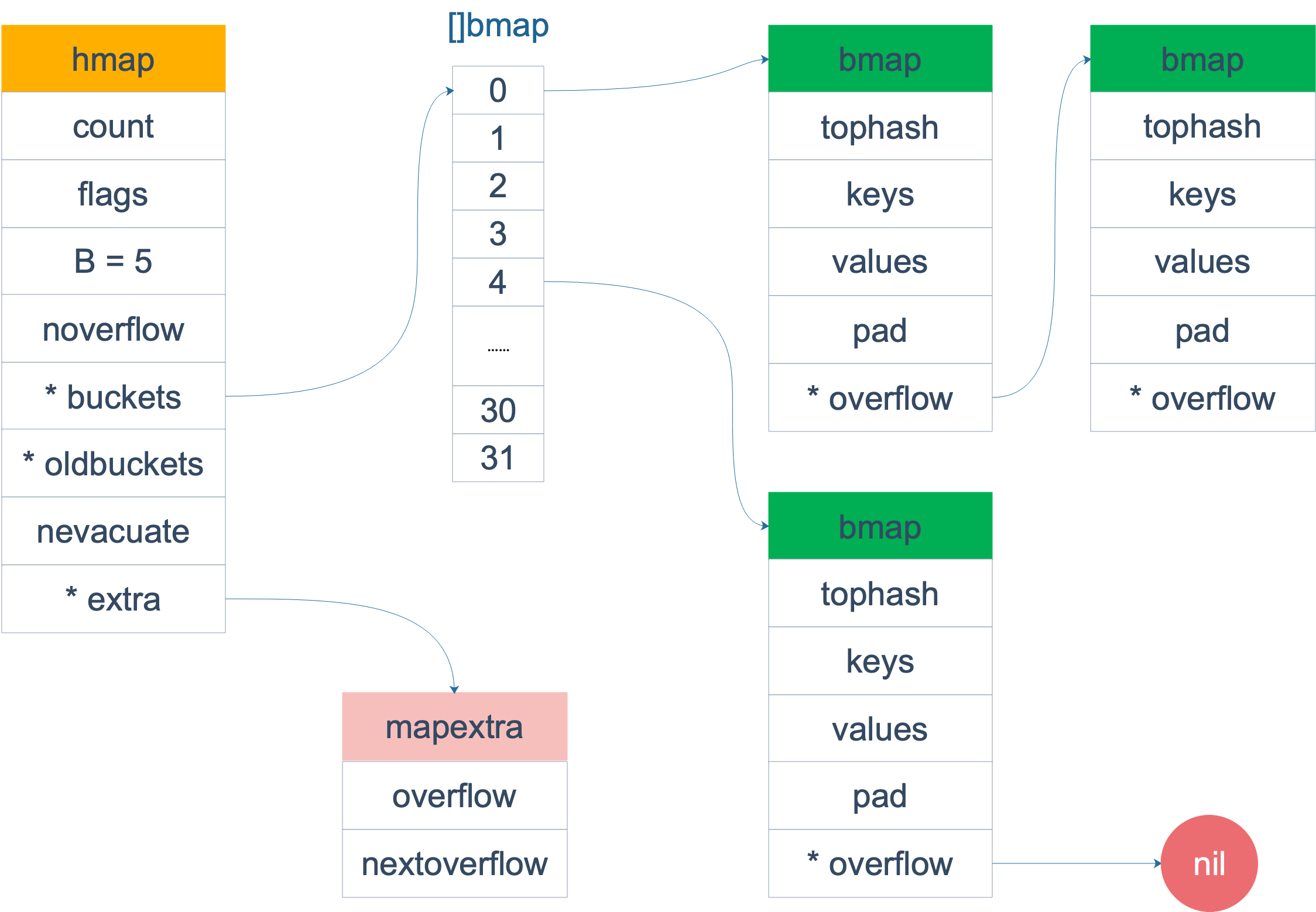
bucket就是bmap
bmap 是存放 k-v 的地方,我们把视角拉近,仔细看 bmap 的内部组成。
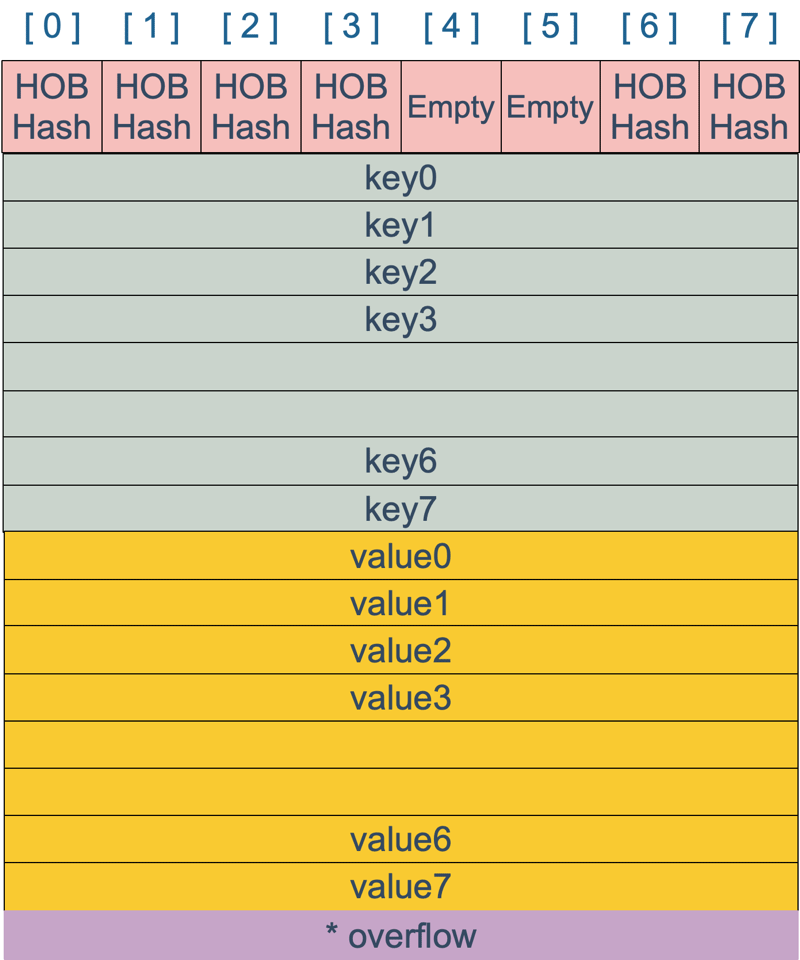
key 经过哈希计算后得到哈希值,共 64 个 bit 位(64位机,32位机就不讨论了,现在主流都是64位机),计算它到底要落在哪个桶时,只会用到最后 B 个 bit 位。还记得前面提到过的 B 吗?如果 B = 5,那么桶的数量,也就是 buckets 数组的长度是 2^5 = 32
例如,现在有一个 key 经过哈希函数计算后,得到的哈希结果是:
10010111 | 000011110110110010001111001010100010010110010101010 │ 01010
用最后的 5 个 bit 位,也就是 01010,值为 10,也就是 10 号桶。这个操作实际上就是取余操作,但是取余开销太大,所以代码实现上用的位操作代替。
再用哈希值的高 8 位,找到此 key 在 bucket 中的位置,这是在寻找已有的 key。最开始桶内还没有 key,新加入的 key 会找到第一个空位,放入。
buckets 编号就是桶编号,当两个不同的 key 落在同一个桶中,也就是发生了哈希冲突。冲突的解决手段是用链表法:在 bucket 中,从前往后找到第一个空位。这样,在查找某个 key 时,先找到对应的桶,再去遍历 bucket 中的 key
hash冲突的两种表示方式:
- 开放寻址法(hash冲突时,在当前index往后查找第一个空的位置即可)
- 拉链法
map在写入过程会发生扩容,runtime.mapassign 函数会在以下两种情况发生时触发哈希的扩容:
- 装载因子已经超过 6.5;装载因子=总数量/桶的数量
- 哈希使用了太多溢出桶;溢出捅的数量 超过正常桶的数量 即 noverflow 大于 1<<B buckets
每次都会将桶的数量翻倍
扩容机制:
- 翻倍扩容:哈希在存储元素过多时状态会触发扩容操作,每次都会将桶的数量翻倍,整个扩容过程并不是原子的,而是通过 runtime.growWork 增量触发的,在扩容期间访问哈希表时会使用旧桶,向哈希表写入数据时会触发旧桶元素的分流;
- 等量扩容,为了解决大量写入、删除造成的内存泄漏问题,哈希引入了 sameSizeGrow这一机制,在出现较多溢出桶时会对哈希进行『内存整理』减少对空间的占用。
